
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2022-06-02 来源:黑马程序员 浏览量:
Hive是基于Hadoop的一个数据仓库工具,主要用来对数据进行抽取、转换、加载操作。HiveQL可以将结构化的数据文件映射为一张数据表,允许熟悉SQL的用户查询数据,也允许熟悉MapReduce的开发者开发自定义的mapper和reducer来处理内建的mapper和 reducer无法完成的复杂的分析工作,相对于Java代码编写的MapReduce来说,Hive的优势更加明显。Hive利用Hadoop的HDFS存储数据,利用Hadoop的MapReduce执行查询。
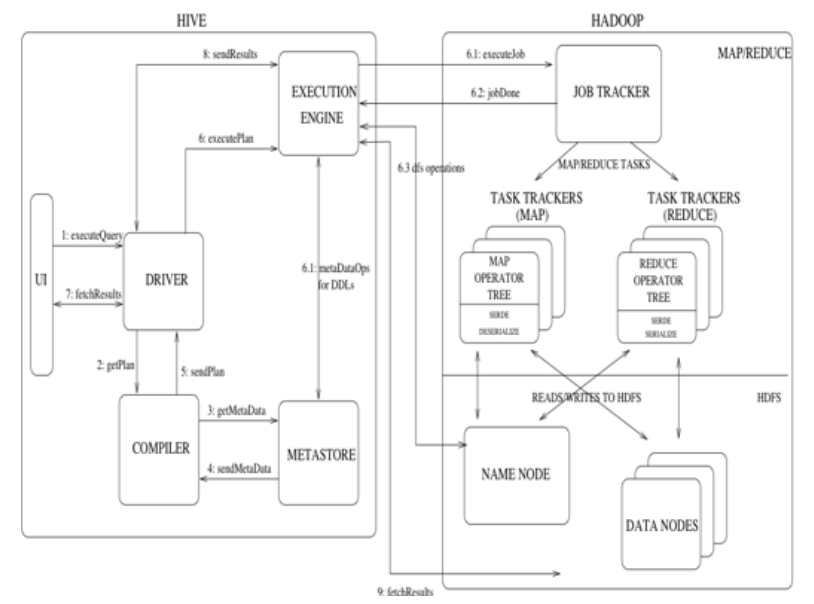
Hive和Hadoop协作执行任务的工作原理
(1) 用户通过用户接口向Driver提交executeQuery。
(2) Driver向Compiler发送获取计划的请求。
(3) Compiler根据用户提交的executeQuery去MetaStore获取需要的元数据信息。
(4) MetaStore向Compiler发送元数据信息。
(5) Compiler得到元数据信息,并向Driver发送计划。
(6) Driver 向EXECUTION ENGINE提交executePlan。
(7) 用户接口向Driver发起获取结果集(fetchResults)的请求。
(8)Driver向EXECUTION ENGINE发起获取结果集的请求。
(9)EXECUTION ENGINE向Driver发送结果集,Driver获取到结果集后返回用户接口。




















.jpg)