
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2024-03-19 来源:黑马程序员 浏览量:

Apache Flink是一个分布式流处理引擎,它支持流一体(stream-batch unification)的特性,这意味着它可以无缝地处理实时流数据和批处理数据,提供了一种统一的编程模型。下面我会尽可能详细地解释Flink如何支持流一体:
Flink提供了一种统一的数据处理模型,称为流处理(Stream Processing)模型。在这个模型中,数据被视为连续不断的流,可以是无界的实时流数据,也可以是有界的批处理数据。Flink通过将所有数据都视为流来实现流一体的特性。
Flink提供了基于流的API,如DataStream API(用于处理实时数据流)和DataSet API(用于处理批处理数据)。这两个API提供了相似的操作符和语义,使得用户可以在处理实时数据和批处理数据时使用相同的编程模型。
Flink支持处理时间(Processing Time)和事件时间(Event Time)两种时间概念。处理时间是数据进入Flink 系统的时间,而事件时间是数据本身携带的时间戳。Flink提供了丰富的时间处理机制,可以在流和批处理作业中使用。
在流处理中,状态管理是非常重要的。Flink提供了可靠且高效的状态管理机制,可以用于处理连续的流数据和有界的批处理数据。这种状态管理机制使得Flink能够处理更复杂的计算任务,如窗口操作、状态管理和容错恢复。
Flink支持各种类型的窗口操作,如滚动窗口、滑动窗口和会话窗口。这些窗口操作可以用于对实时流数据和批处理数据进行分组和聚合操作,使得用户能够方便地处理基于时间的数据窗口。
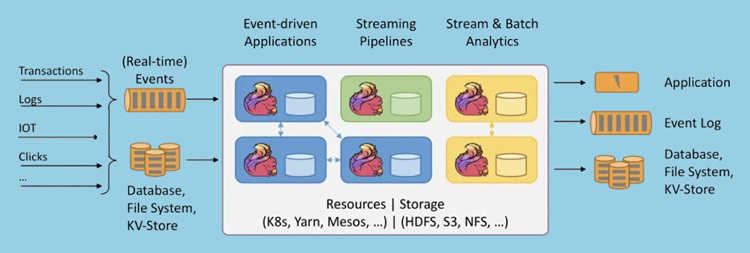
Flink提供了强大的容错机制,可以保证在分布式环境下对流数据和批处理数据进行准确处理。它通过检查点(Checkpoint)机制来实现容错,能够保证在任务失败时进行精确的恢复,从而确保数据处理的完整性和准确性。
Flink具有自适应优化的能力,可以根据当前的运行情况自动调整执行计划。这种动态调优机制可以应用于流处理和批处理作业,以优化资源利用率和提高作业的性能。
Flink提供了丰富的连接器(Connectors),可以轻松地连接各种外部系统,如消息队列、文件系统、数据库等。这些连接器能够处理实时流数据和批处理数据之间的交互,实现流一体的特性。
通过上述方式,Flink实现了流一体的支持,使得用户可以使用统一的编程模型处理实时流数据和批处理数据,从而简化了数据处理的复杂性,提高了系统的灵活性和可扩展性。




















.jpg)