
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2020-12-21 来源:黑马程序员 浏览量:

RDD处理过程中的“转换”操作主要用于根据已有RDD创建新的RDD,每一次通过Transformation算子计算后都会返回一个新RDD,供给下一个转换算子使用。下面,通过一张表来列举一些常用转换算子操作的API,如表1所示。
表1 常用的转换算子API
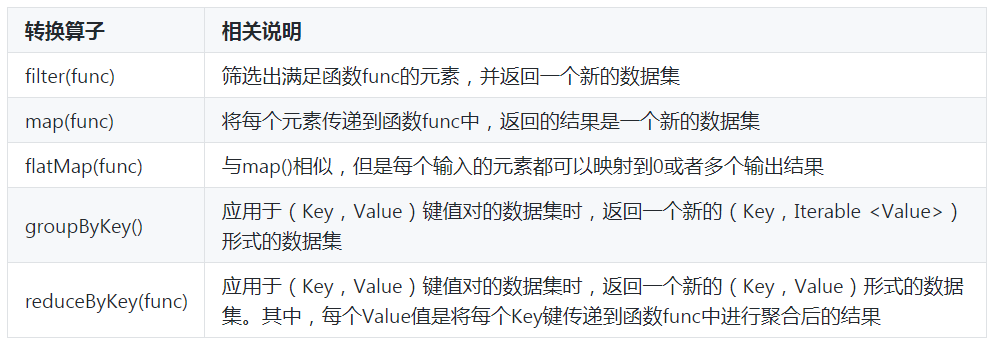
下面,我们通过结合具体的示例对这些转换算子API进行详细讲解。
·filter(func)
filter(func)操作会筛选出满足函数func的元素,并返回一个新的数据集。假设,有一个文件test.txt(内容如文件3-1),下面,通过一张图来描述如何通过filter算子操作,筛选出包含单词“spark”的元素,具体过程如图1所示。
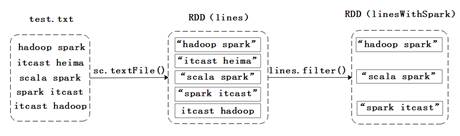
图1 filter算子操作
在图1中,通过从test.txt文件中加载数据的方式创建RDD,然后通过filter操作筛选出满足条件的元素,这些元素组成的集合是一个新的RDD。接下来,通过代码来进行演示,具体代码如下:
scala> val lines = sc.textFile("file:///export/data/test.txt")
lines: org.apache.spark.rdd.RDD[String] = `[file:///export/data/test.txt]`(file:///\\export\data\test.txt)
MapPartitionsRDD[1] at textFile at <console>:24
scala> val linesWithSpark = lines.filter(line => line.contains("spark"))
linesWithSpark: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at
filter at <console>:25在上述代码中,filter()输入的参数line => line.contains(“spark”)是一个匿名函数,其含义是依次取出lines这个RDD中的每一个元素,对于当前取到的元素,把它赋值给匿名函数中的line变量。若line中包含“spark”单词,就把这个元素加入到RDD(即linesWithSpark)中,否则就丢弃该元素。
·map(func)
map(func)操作将每个元素传递到函数func中,并将结果返回为一个新的数据集。假设,有一个文件test.txt(内容如文件1),接下来,通过一张图来描述如何通过map算子操作把文件内容拆分成一个个的单词并封装在数组对象中,具体过程如图2所示。
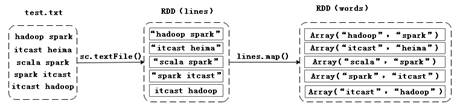
图2 map算子操作
在图2中,通过从test.txt文件中加载数据的方式创建RDD,然后通过map操作将文件的每一行内容都拆分成一个个的单词元素,这些元素组成的集合是一个新的RDD。接下来,通过代码来进行演示,具体代码如下:
scala> val lines = sc.textFile("file:///export/data/test.txt")
lines: org.apache.spark.rdd.RDD[String] = [file:///export/data/test.txt](file:///\\export\data\test.txt)
MapPartitionsRDD[4] at textFile at <console>:24
scala> val words = lines.map(line => line.split(" "))
words: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[13] at
map at <console>:25上述代码中,lines.map(line => line.split(“ ”))含义是依次取出lines这个RDD中的每个元素,对于当前取到的元素,把它赋值给匿名函数中的line变量。由于line是一行文本,如“hadoop spark”,一行文本中包含多个单词,且空格进行分隔,通过line.split(“ ”)匿名函数,将文本分成一个个的单词,拆分后得到的单词都被封装到一个数组对象中,成为新的RDD(即words)的一个元素。
·flatMap(func)
flatMap(func)与map(func)相似,但是每个输入的元素都可以映射到0或者多个输出的结果。有一个文件test.txt(内容如文件3-1),接下来,通过一张图来描述如何通过flatMap算子操作,把文件内容拆分成一个个的单词,具体过程如图3所示。
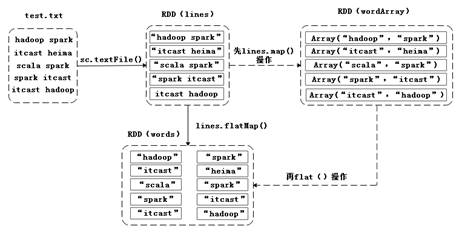
图3 flatMap算子操作
在图3中,通过从test.txt文件中加载数据的方式创建RDD,然后通过flatMap操作将文件的每一行内容都拆分成一个个的单词元素,这些元素组成的集合是一个新的RDD。接下来,通过代码来进行演示,具体代码如下:
scala> val lines = sc.textFile("file:///export/data/test.txt")
lines: org.apache.spark.rdd.RDD[String] = [file:///export/data/test.txt](file:///\\export\data\test.txt)
MapPartitionsRDD[5] at textFile at <console>:24
scala> val words = lines.flatMap(line => line.split(" "))
words: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[14] at
map at <console>:25在上述代码中,lines. flatMap(line => line.split(“ ”))等价于先执行lines.map(line => line.split(“ ”))操作(请参考map(func)操作),再执行flat()操作(即扁平化操作),把wordArray中的每个RDD都扁平成多个元素,被扁平后得到的元素构成一个新的RDD(即words)。
groupByKey()
groupByKey()主要用于(Key,Value)键值对的数据集,将具有相同Key的Value进行分组,会返回一个新的(Key,Iterable)形式的数据集。同样以文件test.txt为例,接下来,通过一张图来描述如何通过groupByKey算子操作,将文件内容中的所有单词进行分组,具体过程如图4示。
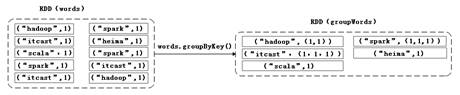
图4 groupByKey算子操作
在图4中,通过groupByKey操作把(Key,Value)键值对类型的RDD,按单词将单词出现的次数进行分组,这些元素组成的集合是一个新的RDD。接下来,通过代码来进行演示,具体代码如下:
scala> val lines = sc.textFile("file:///export/data/test.txt")
lines: org.apache.spark.rdd.RDD[String] = [file:///export/data/test.txt](file:///\\export\data\test.txt) MapPartitionsRDD[6] at textFile at <console>:24
scala> val words=lines.flatMap(line=>line.split(" ")).map(word=>(word,1))
words: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[15] at map at <console>:25
scala> val groupWords=words.groupByKey()
groupWords: org.apache.spark.rdd.RDD[(String,Iterable[Int])]=ShuffledRDD[16]
at groupByKey at <console>:25上述代码中,words.groupByKey()操作执行后,RDD中所有的Key相同的Value都被合并到一起。例如,(“spark”,1)、(“spark”,1)、(“spark”,1)这三个键值对的Key都是“spark”,合并后得到新的键值对(“spark”,(1,1,1))。
reduceByKey(func)
reduceByKey()主要用于(Key,Value)键值对的数据集,返回的是一个新的(Key,Iterable)形式的数据集,该数据集是每个Key传递给函数func进行聚合运算后得到的结果。同样以文件test.txt(内容如文件3-1),接下来,通过一张图来描述如何通过reduceByKey算子操作统计单词出现的次数,具体操作如图5所示。
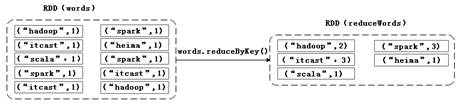
图5 reduceByKey()算子操作
在图5中,通过reduceByKey操作把(Key,Value)键值对类型的RDD,按单词Key将单词出现的次数Value进行聚合,这些元素组成的集合是一个新的RDD。接下来,通过代码来进行演示,具体代码如下:
scala> val lines = sc.textFile("file:///export/data/test.txt") lines: org.apache.spark.rdd.RDD[String] = [file:///export/data/test.txt](file:///\\export\data\test.txt)
MapPartitionsRDD[7] at textFile at <console>:24
scala> val words=lines.flatMap(line=>line.split(" ")).map(word=>(word,1)) words: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[16] at map at <console>:25
scala> val reduceWords=words.reduceByKey((a,b)=>a+b)
reduceWords: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[17] at
reduceByKey at <console>:25 上述代码中,执行words.reduceByKey((a,b) => a +
b)操作,共分为两个步骤,分别是先执行reduceByKey()操作,将所有Key相同的Value值合并到一起,生成一个新的键值对(例如(“spark”,(1,1,1)));然后执行函数func的操作,即使用(a,b)=>
a + b函数把(1,1,1)进行聚合求和,得到最终的结果,即(“spark”,3)。
猜你喜欢




















.jpg)