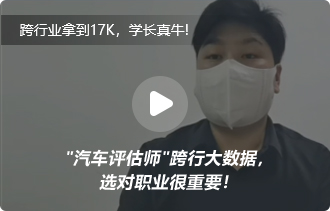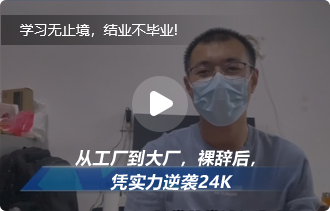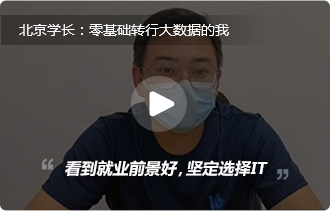
 北京昌平
北京昌平 北京顺义
北京顺义 上海
上海 广州
广州 深圳
深圳 武汉
武汉 郑州
郑州 西安
西安 长沙
长沙 济南
济南 南京
南京 杭州
杭州 成都
成都













积累真经验!
数据来源来自各行业头部大厂

千亿数据 每日数据新增量达200G
还原大厂PB级真实项目

多行业高效通用

助力企业"上云"便捷开发

热门数据岗位全覆盖



-
1
数据库及BI从MySQL入手,到Bl、Kettle的使用,初窥数据开发门径
-
2
Hadoop&Hive技术栈&离线数仓解决方案掌握Hadoop、Hive,构建开发离线数仓大数据平台
-
3
Python编程及数据分析实战掌握Python编程技能,进行ETL实战开发
-
4
Spark技术栈&用户画像解决方案掌握Spark框架及企业级用户画像解决方案
-
5
大模型Agent应用开发掌握Agent构建数据分析领域智能体,助力高效数据分析
-
6
阿里云实时计算Flink技术及项目掌握阿里云Flink技术,强化面试技巧和能力



基于FineReport的BI项目

应用场景ETL数据开发定时调度BI报表设计
企业级真实新零售大数据项目

应用场景多源数据迁移海量数据存储离线数仓设计与实现
基于流批一体架构的新零售大数据项目

应用场景流批一体数据采集流批一体数据存储流批一体数据计算
出行行业流批一体数据仓库

应用场景流批一体数据采集流批一体数据存储流批一体数据计算
基于阿里云的出行大数据项目

应用场景云平台存储云平台计算数据仓库开发



赵老师
Apache Pulsar社区贡献者
擅长数仓领域
从事多年爬虫与大数据开发与教学,对大数据的主流框架有着深入的理解
参与并主导的项目涉及分布式电商,数据爬取,离线分析等多个行业

张老师
Apache Flink源码贡献者
ApacheCon Asia 2022亚洲峰会特邀讲师
曾任网易游戏大数据平台组项目经理、高级专家、技术总监等职务
主导设计游戏一体化大数据运营平台

孔老师
架构师,技术经理
熟悉大数据&数据库&后端&前端
曾在途牛旅游网、江苏移动等公司担任技术经理和架构师,负责优化技术架构和系统流程,解决性能、效率、维护等问题

赵老师
985计算机硕士
ApacheCon Asia 2022亚洲峰会特邀讲师
主导研发多项国家和省级科研项目,负责企业级信贷风控模型和智能医疗数据平台开发
任职头部互联网企业搜索部负责搜索排序及推荐平台研发
大厂背景老师来自京东、百度、小米、搜狐、360、途牛、平安、德邦、上交所等大厂
行业贡献:受邀参加云栖大会、Apache Flink Aisa Metting等行业大会,并发表主旨演讲;Apache Flink社区源码贡献者 2名、Apache Pulsar社区贡献者 1名、Apache Hudi社区贡献者 1名、Apache Doris社区贡献者 1名


在实时计算领域,阿里云实时计算Flink版一直是各大中小企业的主流选择,期待阿里云与传智教育的合作能够培养大量满足企业实际开发需求的实战型人才,助力企业在云上更方便、快捷、低成本的构建大数据分析平台,让企业和学员都能得到受益。
宋辛童(五藏)Apache Flink Committer
阿里巴巴技术专家,北京大学博士

传智教育一直以高质量的教学口碑引领着IT教育培训,积极参与开源贡献并在全球顶级开峰会进行技术分享,其推出的教学视频更是让众多开发者快速的拥抱前沿开源技术,推动了开源项目的发展。期待传智教育推出更多优质的开源课程,让千千万万的IT学子少走弯路,也期待与开源社区继续深入合作,一起把优秀的开源项目推向全球!
李岗ASF Member,Apache DolphinScheduler PMC

中国开源软件的发展和崛起离不开培训机构的大力传播,传智教育作为在IT培训领域知名的机构,推出了大量的开源项目相关的优质视频,让很多想从事IT的小伙伴和从业者能够从中受用。同时传智也有不少老师身体力行地为开源献力:或提交源码、或分享实践、或传道受业解惑,展现了“开源参与你我他”的精神,期待传智教育能够培养出来更多热爱开源的人才,让中国开源软件能够立足中国,贡献全球
代立冬白鲸开源联合创始人、Apache 孵化器导师,亚洲大数据湖仓论坛出品人,中国开源先锋

-

全日制教学管理:每天10小时专属学习计划测试、出勤排名公示,早课+课堂+辅导+测试+心理疏导。
-

实战项目贯穿教学:一线大厂实战项目,实用技术全面覆盖,课程直击企业需求。
-

自研教辅系统:水平测评,目标导向学习,随堂诊断纠错,阶段测评,在线题库,BI报表数据呈现。
-

个性化就业指导:就业指导课,精讲面试题,模拟面试,给出就业建议,试用期辅导,帮助平稳过渡。
-

持续助力职场发展:免费享,更新项目和学习资料、主题讲座,获取行业前沿资讯、人脉经验,线下老学员分享会。
-

无忧学就业权益:多一份安心,学习无忧。
- 1教学管理
- 2项目实战
- 3教辅促学
- 4求职指导
- 5职后提升
- 6无忧学